Ich nutze bereits seit einigen Jahren Docker Container in der Entwicklung, sowie dem Betrieb von Anwendungen und bin begeistert von dieser Technologie. Mit Container lassen sich die eigenen Anwendungen, aber auch jede Drittanwendung in Sekunden auf jedem Server zum Laufen bringen. Man muss sich keine Gedanken zu abhängigen Bibliotheken, verschiedenen Softwareversionen und den parallelen Betrieb von mehreren Anwendungen auf einem Computer machen, da jede Anwendung isoliert in seinem eigenen Container arbeitet.
Neben meiner eigenen Homepage, ein paar Hobby Projekten und einen Blog für meine Reisen betreibe ich auch einige Anwendungen, die ich für meine Arbeit als IT-Consultant benötige, parallel auf einem gemieteten vServer per Docker Container. Neben diesen öffentlichen Anwendungen, habe ich bei mir zu Hause einen Raspberry Pi der ersten Generation laufen, auf welchem ich den Werbeblocker PiHole und die Smart-Home Anwendung Homebridge betrieben habe.
Schon länger interessiere ich mich aber auch für das Thema Container Orchestration via Kubernetes und habe mich schon öfters probiert in das Thema einzuarbeiten. Da ich aber keine passende Hardware hatte bzw. keine drei vServer mieten wollte nur um ein bisschen herumzuspielen, fehlte mir die Möglichkeit die Theorie auch mal in die Praxis umzusetzen. Das Thema Kubernetes wurde von mir nur noch leicht am Rande beobachtet und ich blieb bei meinem Docker bzw. Docker-Compose Setup.
Ende 2020 bin ich dann auf einen Blog Post gestoßen, in dem beschrieben wurde wie man Kubernetes mit drei Raspberry Pis betreibt. Das Interesse war wieder geweckt und ich recherchierte etwas mehr zu dem Thema und stellte fest, dass die 4. Generation des Raspberry Pi auch mit 4 und 8 GB Arbeitsspeicher verfügbar ist und neue Kubernetes Distributionen entwickelt wurden, die auf ARM-Prozessoren laufen und nur wenige Ressourcen in Anspruch nehmen. Die Einstiegshürde für Kubernetes schien nicht mehr so hoch zu sein, weshalb ich mir kurz darauf den ersten Raspberry Pi der 4. Generation bestellt und anfing auf diesem ein Single-Node Kubernetes zu betreiben. In den darauf folgenden Wochen kam ein zweiter und dann ein dritter Raspberry Pi dazu. Schnell bemerkte ich, dass es etwas anderes ist, wenn man mit mehr als einem Node arbeitet. Themen wie persistenter Speicher oder Port-Forwarding am Router funktionieren anders in einem Multi-Node Cluster Setup.
Die letzten Wochen habe ich mich damit beschäftigt mein eigenes Kubernetes Cluster daheim aufzubauen, um meinen gemieteten Server und meinen Raspberry Pi der 1. Generation durch das Cluster abzulösen. Dabei musste ich das ein oder andere Mal das Cluster vollständig Neuinstallieren und war Stunden mit Fehleranalysen beschäftigt. Seit ca. 2 Wochen läuft das Cluster stabil und ich konnte alle Probleme lösen.
Auch, wenn die Einstiegshürde für das eigene Kubernetes-Cluster daheim nicht mehr so hoch ist, wie noch vor 1-2 Jahren, gibt es noch einige Fallstricke und man ist viel mit Fehleranalyse beschäftigt. Damit andere von meiner Erfahrung profitieren können und nicht dieselben Fehler machen wie ich, wollte ich das Thema Raspberry Pi Cluster in einer Serie von Posts auf meiner Webseite thematisieren und anderen näher bringen. Dabei gehe ich weniger auf die Theorie von Kubernetes ein, da es hier bereits sehr viel Literatur und Videos gibt, sondern schreibe viel mehr welche Schritte und Software nötig ist um Kubernetes auf Basis vom Raspberry Pi zu betreiben.
Für wen ist diese Serie und welche Skills sollte man mitbringen?
Die Serie soll sich an diejenigen richten, die sich wie ich für das Thema Kubernetes interessieren, Spaß daran haben neue Technologien auszuprobieren und vorhaben verschiedene Anwendungen, bei sich zu Hause, selbst zu hosten. Von der eigenen Webseite bis hin zur Smart Home Anwendung lässt sich eigentlich fast alles im eigenen Raspberry Pi Cluster daheim betreiben. Auch wenn ich versuche alles detailliert zu beschreiben, setze ich Basis-Skills im Bereich Linux, Netzwerk-Technik und Docker voraus. Sollte man bisher keine Erfahrung mit Docker haben, sollte man erst einmal mit einem einfachen Setup auf Basis von Docker und Docker-Compose anfangen.
Die Hardware
Als Hardware für das Cluster nutze ich den Raspberry Pi der 4. Generation und hierfür gibt es verschiedene Gründe. Zum einen kostet ein Raspberry Pi nicht viel in der Anschaffung und mit ca. 3 -5 Watt Verbrauch ist er auch sehr günstig im Unterhalt (mehr zum Thema Verbrauch findest du hier), aber auch der Platzbedarf macht den Raspberry Pi sehr attraktiv. Mein Cluster, bestehend aus drei Raspberry PIs in einem Gehäuse, nimmt nur wenige Zentimeter Platz in Anspruch und findet überall Platz (aktuell im Weinregal 🍷 von IKEA).

Neben dem Raspberry Pi selbst gibt es bei der restlichen Hardware auch ein paar Dinge zu beachten. Fangen wir mit dem Netzteil an:
Der Raspberry Pi 4 wird per USB-C betrieben und hier würde sich natürlich ein Multi-Port-Netzteil anbieten. Jedoch gibt es hier nicht viele Netzteile die die nötigen 3A/5V auf mehreren Ports gleichzeitig liefern und durch ein Multi-Port-Netzteil besteht das Risiko, dass das ganze Cluster ausfällt, wenn das Netzteil nicht mehr geht. Aus diesem Grund habe ich zum offiziellen Netzteil vom Raspberry Pi gegriffen.
Der nächste Punkt, der bei der Auswahl der Hardware zu beachten ist, ist der verwendete Speicher. Normalerweise nutzt man für den Raspberry Pi eine MicroSD Karte, auf welchem das Betriebssystem läuft und auf dem alle Daten gespeichert werden. Im Internet habe ich jedoch oft gelesen, dass SD Karten sehr unzuverlässig sind und daher nicht für den Cluster Dauerbetrieb geeignet sind. Seit 2020 unterstützt der Raspberry Pi das Boot von USB, weshalb ich anstatt einer MicroSD Karte einen USB Stick nutze. Neben der der besseren Verlässlichkeit, Punkte USB 3.1 Sticks auch mit einer höheren Geschwindigkeit im Gegenstz zu MicroSD Karten. Und Geschwindigkeit ist ein wichtiger Punkt in einem Cluster, wo Daten schnell zwischen mehreren Nodes synchronisiert werden müssen. Ich hatte erst zu langsamen Speicher Sticks gegriffen, die zu einem sehr unzuverlässigen Cluster geführt haben. Nachdem mir mein Fehlgriff bewusst wurde und ich auf schnellere Speicher gewechselt haben, läuft mein Cluster ohne Probleme. Bei der Speichergröße habe ich mich für 64 GB entschieden, was erst einmal ausreichend sein sollte.
Shopping-Liste 🛒
- Raspberry Pi 4. Generation 4 GB Arbeitsspeicher
- Raspberry Pi Netzteil
- Samsung FIT Plus 64GB 300 MB/s USB 3.1
- Cluster Gehäuse
Betriebssystem
Beim Betriebssystem habe ich mich für Ubuntu 20.04 LTS 64 Bit entschieden, da es das offizielle Raspberry Pi Betriebssystem Raspbian OS bisher noch nicht in einer stabilen 64 Bit Version gibt. Zwar nutze ich bisher nur 4 GB Modelle und könnte auch 32 Bit nutzen, aber sollte ich in Zukunft mir ein 8 GB Modell kaufen, müsste ich spätestens dann auf ein 64 Bit Betriebssystem wechseln. Ein weiterer Punkt der für 64 Bit spricht ist, dass es die Software Longhorn (mehr zu Longhorn in Teil 2) nur in einer 64 Bit Version gibt.
Installation
Um das Betriebssystem zu installieren, kann man "Raspberry Pi Imager" nutzen. Die nachfolgenden Schritte führt man pro Raspberry Pi durch:
- Wähle in Raspberry Pi Imager als Erstes das Betriebssystem aus.

- Ubuntu findest du unter dem Menü-Punkt "other general purpose OS".
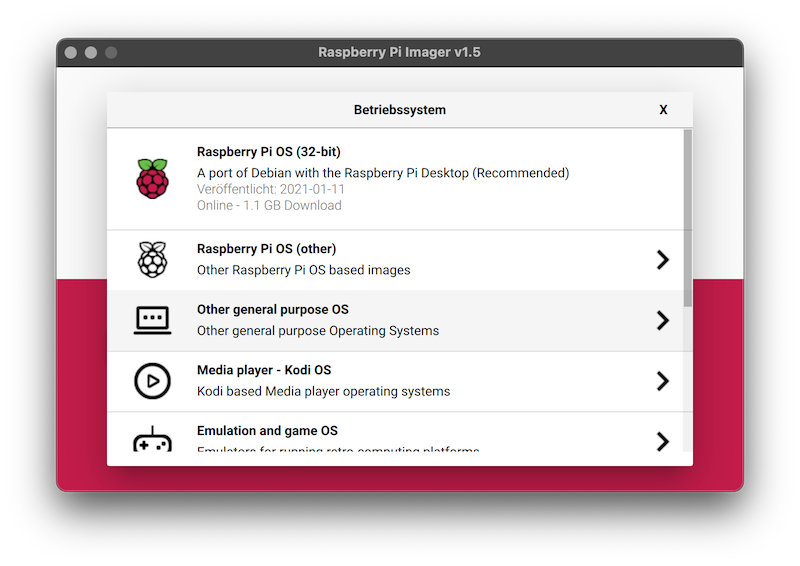
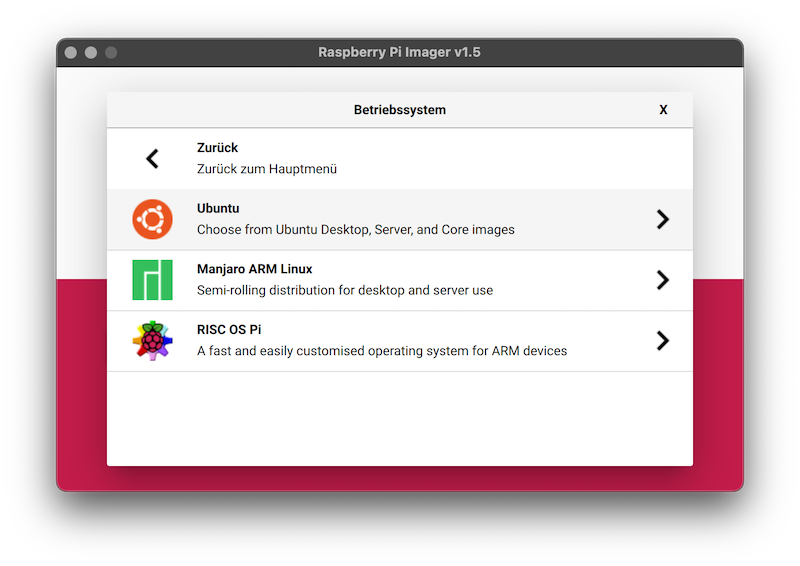
-
Wähle Ubuntu 20.04 LTS 64 Bit aus.
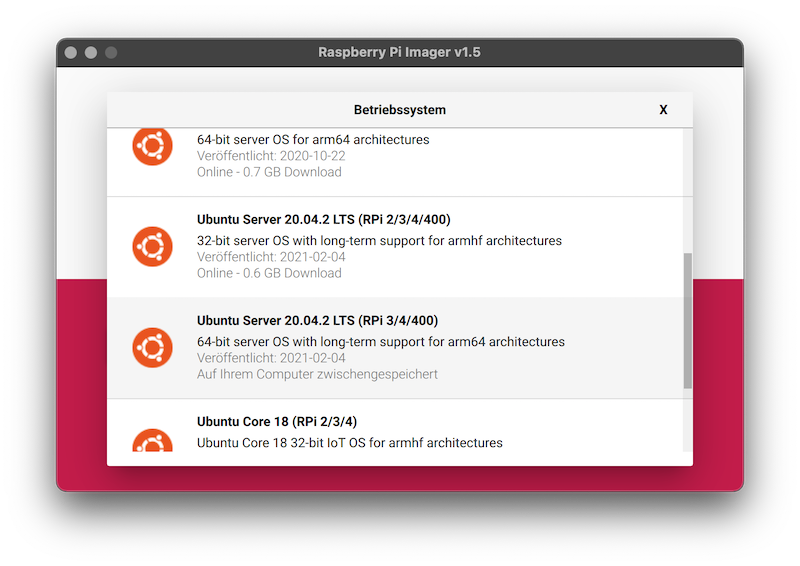
-
Anschließend muss der USB-Speicher ausgewählt werden.

-
Und klicke "schreiben" um das Betriebssystem auf den USB Stick zu übertragen.

Sobald der Vorgang abgeschlossen ist, müssen wir noch einen letzten Schritt durchführen.
Das Cluster wird im Headless-Modus, also ohne Monitor und Tastatur, betrieben, weshalb es nötig ist den SSH Dienst zu aktivieren. Um den SSH Dienst zu aktiveren, muss der USB Stick aus und wieder einsteckt werden. Es sollte ein Laufwerk mit dem Namen "system-boot" erscheinen. Auf diesem erstellt man eine leere Datei mit dem Namen ssh.
Auf dem Mac geht dies ganz einfach mit dem Befehl touch /Volumes/system-boot/ssh
Nun können wir den Stick in den Raspberry Pi stecken und alles für die Kubernetes Installation vorbereiten. Bei mir wollte Ubuntu jedoch nicht vom USB Stick booten und nach einer kleinen Recherche bin ich auf diesen Post gestoßen, welcher erklärt wie man das Problem löst: Raspberry Pi 4 Ubuntu 20.04 / 20.10 USB Mass Storage Boot Guide.
Vorbereitung
Bevor wir die Kubernetes Installation durchführen können, müssen wir einige Anpassungen pro Raspberry Pi vornehmen. Hierfür verbinden wir uns per SSH mit den Raspberry Pis und führen auf allen dieselben Schritte durch. Die IP-Adressen der Raspberry Pis können über den Router festgestellt werden, wo man am besten auch direkt eine feste IP-Adresse vergibt.
Beim Verbinden per SSH mit dem Benutzer ubuntu wird man nach einem Passwort gefragt, welches standardmäßig ubuntu ist. Dies Passwort muss beim ersten Login geändert werden. Sobald dies getan ist, können wir loslegen.
Als Erstes vergibt man einen Hostname:
hostnamectl set-hostname pi-01Dieser Hostname wird später in Kubernetes angezeigt. Ich habe meine Raspberry Pis einfach durchnummeriert.
Nach der vergab des Hostnames, löschen wir den Package-Manager snap, da wir dies nicht benötigen, und installieren neue Updates:
snap list
sudo snap remove lxd && sudo snap remove core18 && sudo snap remove snapd
sudo apt purge snapd -y
sudo apt autoremove -y
sudo apt update -y
sudo apt upgrade -yNachdem die Software auf dem neusten Stand ist, schalten wir die Container Feature vom Kernel ein und erlauben das Mithören des Bridge-Traffics im Cluster:
# Enable Container Feature
sudo sed -i '$ s/$/ cgroup_enable=cpuset cgroup_enable=memory cgroup_memory=1 swapaccount=1/' /boot/firmware/cmdline.txt
# Allow listing on bridge traffic
sudo nano /etc/sysctl.d/k3s.conf
# add:
# net.bridge.bridge-nf-call-ip6tables = 1
# net.bridge.bridge-nf-call-iptables = 1Um die Änderungen zu übernehmen ist ein Neustart erforderlich:
sudo rebootAls letzten Schritt übertragen wir den SSH-Key vom eigenen Computer auf den Raspberry Pi, damit man sich in Zukunft ohne Passwort anmelden kann und deaktiviert anschließend den Login via Password:
ssh-copy-id -i ~/.ssh/id_rsa.pub ubuntu@<IP>
ssh ubuntu@<IP>
sed -i "s/.*PasswordAuthentication.*/PasswordAuthentication no/g" /etc/ssh/sshd_config
sudo service sshd restartSind diese Schritte auf allen Raspberry Pis durchgeführt, kann Kubernetes installiert werden.
K3s
K3s? Wollten wir nicht Kubernetes (K8s) installieren? K3s ist eins von vielen Kubernetes Distributionen (Übersicht), welches den Fokus auf Edge, IoT und ARM legt. K3s bezeichnet sich selbst als "Lightweight Kubernetes" und benötigt auf einem Server Node nur 500 MB Arbeitsspeicher und 50 MB auf einem Agent Node. Auch der Name K3s soll zeigen, dass es sich um ein schlankes Kubernetes handelt:
We wanted an installation of Kubernetes that was half the size in terms of memory footprint. Kubernetes is a 10-letter word stylized as K8s. So something half as big as Kubernetes would be a 5-letter word stylized as K3s. There is no long form of K3s and no official pronunciation.
Für die Installation von k3s nutzen wir das Tool k3sup, um die Installation automatisch per SSH durchzuführen. Ist k3sup installiert (Installationsanleitung), brauchen wir nur drei Befehle um das Cluster vollständig zu installieren:
# Setup K3S Cluster
k3sup install --ip <ip-node-1> \
--user ubuntu \
--k3s-extra-args '--disable servicelb,traefik,local-storage' \
--ssh-key ~/.ssh/<ssk-key-name>
# Join second server
k3sup join --ip <ip-node-2> \
--user ubuntu \
--server --k3s-extra-args '--disable servicelb,traefik,local-storage' \
--server-ip <ip-node-1> --server-user ubuntu \
--ssh-key ~/.ssh/<ssk-key-name>
# Join Agent
k3sup join --ip <ip-node-3> \
--user ubuntu \
--server-ip <ip-node-1> --server-user ubuntu \
--ssh-key ~/.ssh/<ssk-key-name>Mit dem ersten Befehl installieren wir auf dem ersten Node einen k3s Server, welcher die Verwaltung des Clusters übernimmt. Durch den Parameter --cluster wird anstatt einer lokalen SQLite Datenbank das verteilte Speicher-System etcd installiert, welches genutzt wird um den Cluster Zustand und die Cluster Einstellungen zwischen mehreren Server-Nodes zu syncronisieren (weitere Informationen zu etcd findet ihr hier). Wir haben hierdurch die Möglichkeit, einen weiteren Server-Node zu installieren um ein High-availability Cluster zu erhalten. Fällt ein Server-Node aus, kann ein anderer Server-Node die Verwaltung des Clusters weiterführen. Ich habe mich dazu entschieden in meinem drei Node-Cluster zwei Nodes mit der Verwaltung des Clusters zu beauftragn.
Desweiteren deaktiveren wir den mitgelieferten Loadbalancer-Service, Speicher-Provider und Traefik (v1) mit der Option --k3s-extra-args '--disable servicelb,traefik,local-storage'. Dies ist nötig, da wir später MetalLB als Loadbalancer-Service, Longhorn als Speicher-Provider und Version 2 von Traefik installieren werden. Würden wir die mitgelieferten Services nicht deaktivieren, kommt es später zu Konflikten innerhalb des Clusters.
Mit dem zweiten Befehl fügen wir einen weiteren Server-Node dem Cluster hinzu. Hierfür verwenden wir den join Befehl mit dem Parameter --server. Es ist wichtig, beim hinzufügen von weiteren Server-Nodes die Option --k3s-extra-args '--disable servicelb,traefik,local-storage' mit zugeben! Anderfalls würde der hinzugefügt Server die nicht gewünschten Services installieren.
Mit dem dritten Befehl fügen wir den letzten Raspberry Pi als Agent-Nodes hinzu, womit unsere Cluster-Installation abgeschlossen ist.
K3sup legt im aktuellen Verzeichnis die Datei kubeconfigab, welche die für den Cluster-Zugriff nötigen Zertifikate und Access-Token enthält. Als nächstes installieren wir das CLI-Tool kubectl um auf das Cluster zuzugreifen: Installieren und konfigurieren von kubectl. Nach der Installation schreiben wir den Pfad der kubeconfig Datei in die Umgebungsvariable KUBECONFIG (damit kubectl weiß wo die Datei gespeichert ist), setzen den context 'default' als aktiven context und lassen uns alle Nodes anzeigen.
export KUBECONFIG=`pwd`/kubeconfig
kubectl config set-context default
kubectl get node -o wideWenn alles geklappt hat, sollten wir alle Nodes sehen können und unser Cluster ist Einsatzbereit.

Was kommt als nächstes
In Teil 2 der Serie werden wir MetalLB, Longhorn, Cert-Manager und Traefik v2 installieren, wodurch wir alle Grundlagen schaffen um sowohl öffentliche als auch private Services/Applications in unserem Cluster zu betreiben.