
Raspberry Pi Kubernetes Cluster (Teil 2)
02.05.2021Im ersten Teil dieser Serie haben wir ein k3s Kubernetes Cluster installiert, auf welchem jedoch noch keine Anwendung läuft. In diesem Teil beschäftigen wir uns damit, wie man Anwendungen dem Cluster hinzufügt und welche Dienste benötigt werden, um Anwendung öffentlich per HTTPs oder privat im eigenen Netzwerk zu betreiben. Hierbei werden Themen wie Load-Balancing, TLS Zertifikate und persistenter Speicher eine Rolle spielen. Das Ziel ist es, einen öffentlichen Wordpress-Blog, den DNS Dienst pi.hole und die Smart Home Anwendung Home Assistant im Cluster zu betreiben. Wie im ersten Teil bereits erwähnt, werde ich nicht auf die Theorie zu Kubernetes eingehen und verweise an dieser Stelle auf die offizielle Dokumentation von Kubernetes: kubernetes.io
Anwendungen dem Cluster hinzufügen
Wie im ersten Teil beschrieben, kümmert sich ein Server Node um die Verwaltung des Clusters, weshalb wir auch mit einem Server Node kommunizieren müssen, um etwas im Cluster zu machen. Für die Kommunikation stellt ein Server Node eine API bereit mit welcher wir, z.B. über das CLI-Tool kubectl, kommunizieren können.
Kubectl
Kubectl haben wir bereits im ersten Teil installiert und benutzt, um uns die Nodes im Cluster anzeigen zu lassen. Wir nutzen kubectl auch um neue Kubernetes Objekte zu erstellen, wie in diesem Beispiel, bei dem ein Deployment und ein Service erstellt wird:
kubectl create deployment hello-world --image=containous/whoamikubectl expose deployment/hello-world --port=8080Es wäre jedoch sehr aufwendig das gewünschte Setup mit einzelnen Befehlen zu erstellen, weshalb man das gewünschte Setup, wie z.B. bei Docker-Compose, in einer YAML-Datei beschreibt und kubectl nutzt, um die Konfiguration zu übernehmen. Die nachfolgende YAML-Config erstellt, wie das Beispiel oben, ein Deployment und einen Service (Hinweis: Jedes Kubernetes Objekt muss in einer separaten Datei beschrieben werden, das Einfügen von --- erlaubt das zusammenfügen mehrerer Dateien in einer Datei):
kind: DeploymentapiVersion: apps/v1metadata: name: hello-world labels: app: hello-worldspec: replicas: 1 selector: matchLabels: app: hello-world template: metadata: labels: app: hello-world spec: containers: - name: hello-world image: datenfahrt/aarch64-hello-world ports: - name: http containerPort: 8080---apiVersion: v1kind: Servicemetadata: name: hello-world labels: app: hello-worldspec: ports: - protocol: TCP port: 8080 targetPort: web selector: app: hello-worldMit dem nachfolgenden Befehl übernehmen wir die YAML-Config:
kubectl apply -f hello-world.yamlMöchte man für eine bessere Übersicht die Kubernetes Objekte in separaten YAML-Dateien spezifizieren, bietet es sich an diese in einem gemeinsamen Ordner abzulegen und die Dateien in einer logischen Reihenfolge durchzunummerieren. Eine YAML die einen Namespace spezifiziert, sollte mit 1 anfangen, da der Namespace vor allem anderen erstellt werden sollte. Dasselbe gilt für Secrets, Configmaps oder PVC auf die z.B. ein Deployment zugreift. Hat man alles logisch durchnummeriert, kann man den vollständigen Ordner an kubectl übergeben
kubectl apply -f hello-world/Helm Chart
Möchte man eine neue Anwendung dem Cluster hinzufügen, bietet es sich an vorab zu recherchieren, ob es bereits YAML-Beispiele im Internet gibt, welches man wiederverwenden kann. Verwendet man YAML Dateien von anderen Personen wieder, muss man jede Einstellung prüfen, ob diese für einen auch gilt oder ob man sie ggf. Ändern muss.
An dieser Stelle kommt Helm ins Spiel. Helm ist ein Package-Manager für Kubernetes, welcher einem viel Arbeit bei der Installation von Anwendungen abnimmt.
Mit Helm ist es möglich, dass andere Personen sogenannte Helm Charts bereitstellen, die von anderen verwendet werden können, um eine Anwendung zu installieren.
Technisch besteht ein Helm Chart aus mehreren YAML Dateien, die als Template fungieren in welchen Variablen oder Bedingungen definiert sind. In einer YAML-Datei (values.yaml) legt man die gewünschten Einstellungen fest, die auf das Template angewendet werden soll. Installiert man nun einen Helm Chart nutzt Helm die values.yaml und die Templates und generiert daraus die eigentlichen YAML-Konfigurationen die anschließend an das Kubernetes Cluster gesendet werden. Bei der Installation kann man eine eigene values.yaml Datei mitgeben, um so das Setup anzupassen. In dieser values.yaml müssen auch nur die gewünschten Einstellungen definiert werden, da Helm die eigene values.yaml mit der Standard values.yaml des Helm Charts zusammenführt.
Nach der Installation, kann man über artifacthub.io nach einem Helm Chart suchen. Hat man das gewünschte Helm Chart gefunden, muss man das Repo des Helm Chart Anbieters hinzufügen:
helm repo add nicholaswilde https://nicholaswilde.github.io/helm-charts/helm repo updateHat man das Repo hinzugefügt, kann man die Standard values.yaml lokal speichern:
helm show values nicholaswilde/hedge > values.yamlIn der values.yaml findet man nun alle Einstellungen die man vornehmen kann:
image: repository: ghcr.io/linuxserver/hedgedoc pullPolicy: IfNotPresent tag: "1.7.2-ls11"secret: {}env: TZ: "America/Los_Angeles"service: port: port: 3000ingress: enabled: true hosts: - host: "hedgedoc.192.168.1.203.nip.io" paths: - path: / pathType: Prefix tls: []persistence: config: enabled: false emptyDir: false mountPath: /config accessMode: ReadWriteOnce size: 1Gi skipuninstall: falsemariadb: enabled: false secret: {} env: {} persistence: config: enabled: false emptyDir: false mountPath: /config accessMode: ReadWriteOnce size: 1Gi skipuninstall: falseMöchte man nur bestimmte Einstellung ändern und den Rest beim Standard belassen, kann man nur diese Einstellungen in der values.yaml belassen. Möchte man z.B. nur die Timezone anpassen und das Einrichten eines Ingress unterbinden, reicht eine values.yaml mit folgendem Inhalt:
env: TZ: "Europe/Berlin"ingress: enabled: falseHat man die gewünschten Anpassungen vorgenommen, kann man das Helm Chart installieren:
helm install hedgedoc nicholaswilde/hedgedoc --values values.mlAlternativ zum install Befehl kann man auch den upgrade Befehl zusammen mit dem --install Parameter nutzen:
helm upgrade --install hedgedoc --values values.yaml nicholaswilde/hedgedocDer Vorteil beim upgrade Befehl ist, dass man die value.yaml nachträglich anpassen kann und denselben Befehl nutzt, um die Änderung an einem bereits installierten Helm Chart vorzunehmen.
MetalLB als Load-Balancer
Betreibt man Kubernetes in der Cloud oder einem Rechenzentrum, verfügt man in der Regel über einen Software oder Hardware Load-Balancer, welcher die Last auf alle Nodes verteilt. Im privaten Bereich hat man hingegen selten solch einen Load-Balancer, weshalb wir zu einer anderen Lösung greifen müssen.
Natürlich stellt sich die Frage, warum man überhaupt einen Load-Balancer in diesem Setup braucht, denn eigentlich kümmert sich Kubernetes um die Lastverteilung zwischen den Pods welche ggfs. auf verschiedenen Nodes laufen. Neben der Lastverteilung sorgt ein Load-Balancer auch dafür, dass eingehende Netzwerk-Anfragen nur an verfügbare Nodes gesendet werden und stellt so die Verfügbarkeit sicher. Fällt einer der Nodes aus, können die verbleibenden Nodes die Anfragen entgegennehmen. Zu diesem Zweck werden die Netzwerk-Anfragen nicht an eine der Node IP-Adressen direkt gesendet, sondern an die IP-Adresse des Load-Balancer.
Um solche eine IP-Adresse auch ohne Software oder Hardware Load-Balancer zu erhalten, nutzen wir den Dienst MetalLB, welcher uns virtuelle IP-Adressen bereitstellt. Diese virtuellen IP-Adressen können genutzt werden, um Netzwerk-Anfragen an einen der verfügbaren Cluster Nodes zu senden. Um solche eine virtuelle IP-Adresse zu erzeugen, installiert MetalLB auf jedem Node einen Speaker-Pod. Kommt nun ein ARP-Request für eine virtuelle IP-Adresse bei den Nodes an, antwortet MetalLB auf diesen Request mit einer der MAC-Adressen der Cluster-Nodes. Hierdurch empfängt der Node, welcher die zurückgegeben MAC-Adresse besitzt, zukünftig Netzwerk-Pakete für die virtuelle IP-Adresse. Ein Node erhält hierdurch mehrere IP-Adressen im Netzwerk. Fällt dieser Node aus, informiert MetalLB alle Clients im Netzwerk, dass nun eine anderer Node die virtuellen IP besitzt (mehr zum Thema hier).
MetalLB installieren wir mit kubectl und verwenden hierfür die YAML-Dateien aus dem offiziellen GitHub-Repo:
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/main/manifests/namespace.yamlkubectl apply -f https://raw.githubusercontent.com/metallb/metallb/main/manifests/metallb.yamlkubectl create secret generic -n metallb-system memberlist --from-literal=secretkey="$(openssl rand -base64 128)"Nach der Installation müssen wir MetalLB noch den IP-Adressen Bereich mitteilen, für welches es zuständig ist. Dies geschieht durch eine ConfigMap welche wir in einer YAML-Datei spezifizieren und anschließend per kubectl übernehmen:
apiVersion: v1kind: ConfigMapmetadata: namespace: metallb-system name: configdata: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.178.20-192.168.178.39Hinweis: Im Router sollte der DHCP Dienst keine IP-Adresse im selben IP-Adressen Bereich vergeben, da es sonst zu Konflikten kommt
kubectl apply -f address-pool.yamlNach der Installation sollte man einen Controler-Pod und pro Node einen Speaker-Pod sehen:
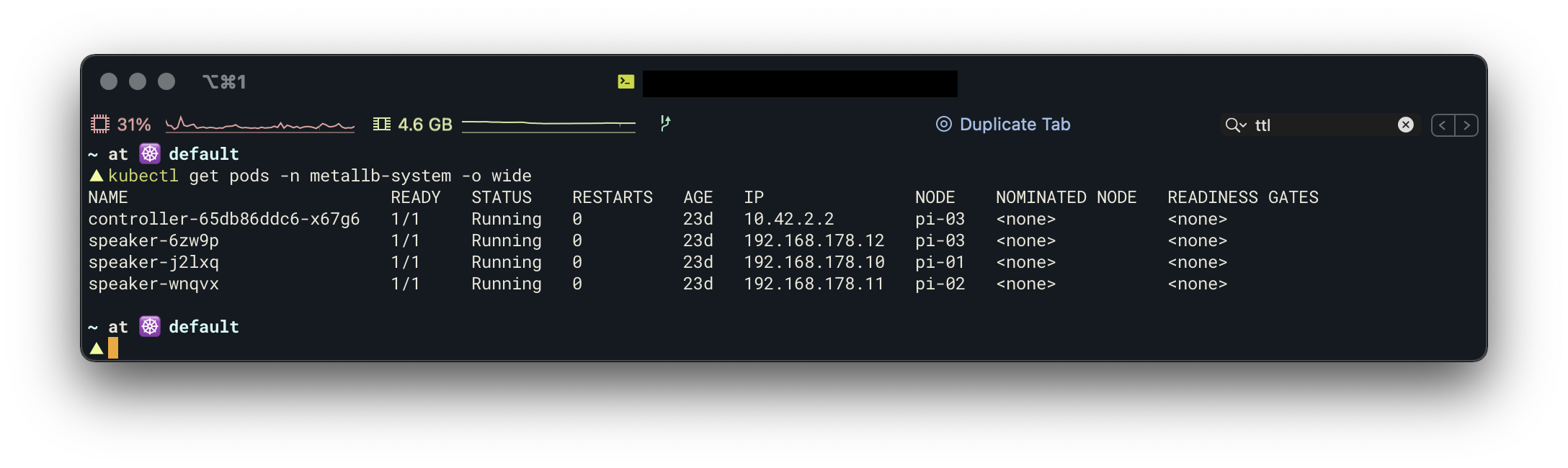
Traefik v2 als Ingress
Traefik ist ein Application Proxy, welchen ich schon länger in Zusammenhang mit Docker nutze. Besonders schätze ich die einfache Handhabung von Traefik was das Definieren von Routing Regeln angeht und dass Traefik sich selbst um TLS Zertifikate kümmert. So konnte ich in meinem alten Docker-Compose Setup durch das Einfügen von nur 5 Labels einen Docker-Service per HTTPS öffentlich bereitstellen. Wir nutzen Traefik in unserem Kubernetes Setup als Ingress Controller, welcher basierend auf Routing-Regeln eingehende Requests zu den entsprechenden Services routet und sich auch um die TLS Terminierung kümmert. Zusätzlich nutzen wir einige der mitgelieferten Middlewares von Traefik um die Sicherheit zu erhöhen.
Für die Installation von Traefik nutzen wir das offizielle Helm Chart:
helm repo add traefik https://helm.traefik.io/traefikhelm repo updateBevor wir Traefik installieren, erstellen wir eine YAML-Datei, um ein paar Einstellungen zu definieren:
deployment: enabled: true kind: DaemonSetingressRoute: dashboard: enabled: falselogs: general: level: ERROR access: enabled: trueadditionalArguments: - "--api.dashboard=true" - "--providers.kubernetesingress.ingressclass=traefik-cert-manager"ports: traefik: port: 9000 expose: false exposedPort: 9000 protocol: TCP web: port: 8000 expose: true exposedPort: 80 protocol: TCP websecure: port: 8443 expose: true exposedPort: 443 protocol: TCP tls: enabled: trueservice: enabled: true type: LoadBalancer externalTrafficPolicy: Local externalIPs: - 192.168.178.20Viele der definierten Einstellungen entsprechen der Standard-Einstellung des Helm Charts. Ich lasse sie aber bewusst in der YAML-Datei, um eine gute Sicht darüber zu erhalten wie mein Setup aussieht.
Ich installiere Traefik als DaemonSet um auf jedem Node einen Traefik Pod laufen zu haben. Alternativ kann man Traefik auch als Deployment installieren. Die Pro und Cons zwischen beiden Varianten findet man hier. Das automatische Erstellen einer Ingress-Route für das Traefik-Dashboard habe ich deaktiviert, da ich später selbst eine Ingress-Route definieren möchte. In den zusätzlichen Argumenten habe ich einen Namen für die Ingress-Class definiert, welchen wir später für den Cert-Manager benötigen. Beim Service nutze ich den Type "Load-Balancer", welchem ich die virtuelle IP 192.168.178.20 zuweise. Über diese IP ist später Traefik erreichbar.
Sind alle Einstellungen wie gewünscht definiert, können wir Traefik per Helm installieren:
helm upgrade --install --values=config.yaml --namespace kube-system traefik traefik/traefikUm das Setup zu testen, kann man im Browser die definierte IP-Adresse eingeben. Es sollte eine "404 page not found" Fehlermeldung erscheinen. Diese Fehlermeldung ist vollkommen in Ordnung, da noch keine Routing-Regeln existieren. Sie zeigt aber, dass der Request bei Traefik ankommt.
Erste Anwendung
Nach der Installation von Traefik und MetalLB sind alle Voraussetzungen gegeben, um HTTP-Anwendungen im Cluster aufzurufen. Da wir uns noch nicht mit dem Themen Port-Forwarding, TLS-Zertifikate und persistenter Speicher beschäftigt haben, ist das Dashboard von Traefik unsere erste Anwendung, die wir für uns verfügbar machen. Das Dashboard wird von Traefik mitgeliefert und muss keine Daten speichern, weshalb das Einrichten sehr einfach ist.
Um HTTP-Anfragen an das Dashboard zu routen, fehlt eine IngressRoute welche Routing-Regeln definiert.
Die nachfolgende YAML-Datei definiert eine Routing-Regel für den Entry-Point web (http) und hat nur die Bedingung, dass der Host-Header im HTTP-Request traefik ist. Da wir das Dashboard nur über das eigene Netzwerk verfügbar machen, können wir den Hostname frei wählen. Bei öffentlichen Anwendungen muss man als Hostname die eigene (Sub-)Domain eintragen. Neben dem Prüfen des Hostnames gibt es noch weitere Regeln, welche auch kombiniert werden können.
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: traefik-dashboard namespace: kube-systemspec: entryPoints: - web routes: - match: Host(`traefik`) kind: Rule services: - name: api@internal kind: TraefikServiceDie YAML-Datei wird wieder wie gewohnt mit kubectl übernommen.
Um das Dashboard vom lokalen Computer aufzurufen, muss der Hostname mit der virtuellen IP verknüpft werden. Hierfür wird vorerst die lokale Host Datei (Windows: C:\Windows\System32\drivers\etc\hosts und MacOS/Linux: /etc/hosts) verwendet. In dieser Datei trägt man die virtuelle IP gefolgt vom definierten Hostname ein.
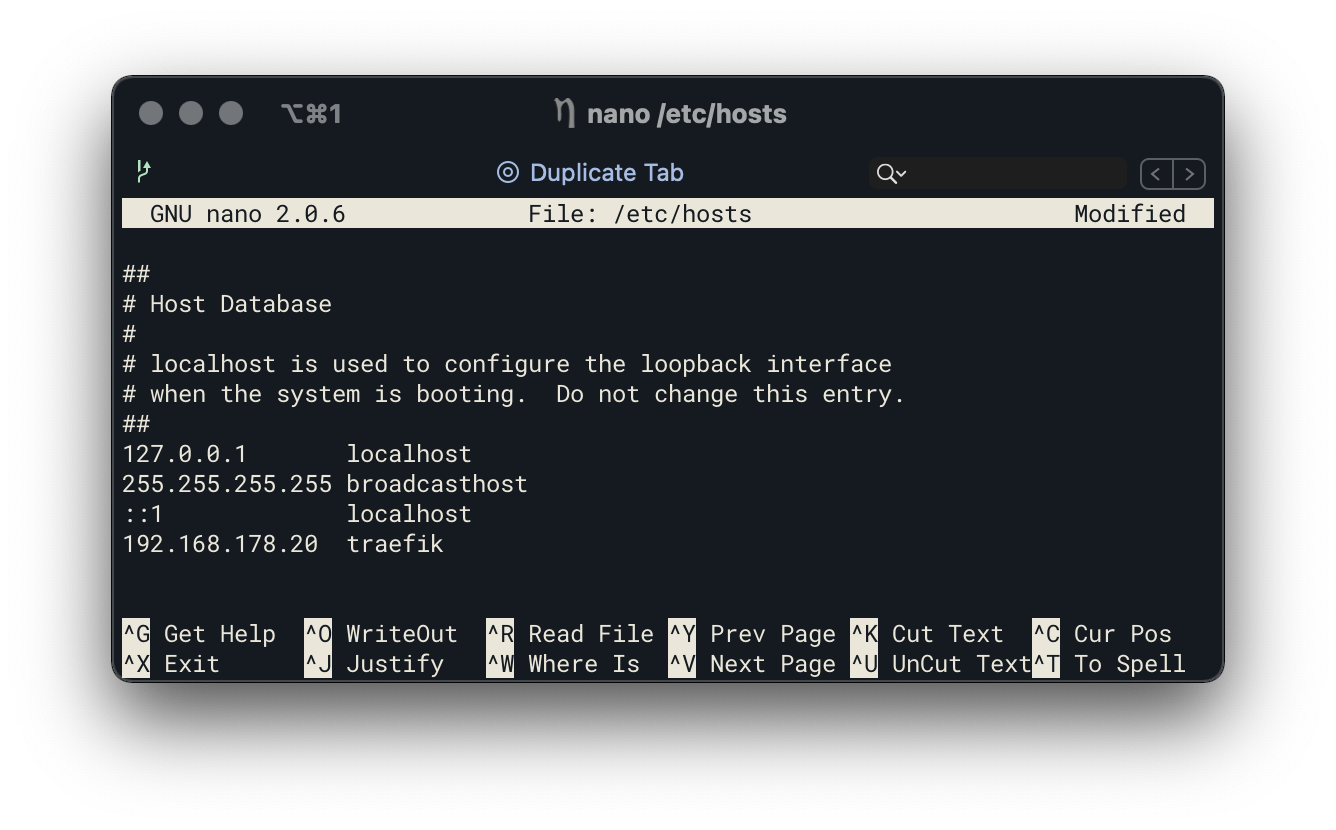
Tipp man nun in den Browser http://traefik ein, erscheint das Dashboard von Traefik
Basic Auth Middleware
Das Dashboard von Traefik kommt ohne Passwortschutz und ist für jedem im Netzwerk aufrufbar. Zwar lassen sich über das Dashboard keine Änderungen vornehmen, aber ein Passwortschutz ist nicht verkehrt.
Um das Dashboard mit einem Passwort zu schützen, nutzen wir die Basic-Auth Middleware von Traefik. Diese Middleware erwartet die Basic-Auth Zugangsdaten als Secret:
# https://docs.traefik.io/middlewares/basicauth/#users# Note: in a kubernetes secret the string (e.g. generated by htpasswd) must be base64-encoded first.# To create an encoded user:password pair, the following command can be used:# htpasswd -nb user password | openssl base64apiVersion: v1kind: Secretmetadata: name: traefik-basic-auth namespace: kube-systemdata: users: dXNlcjokYXByMSRtVy5UTjR3ZyRCTW1nZExSZ0FJNkNQWmtXb09oOUkvCgo=Nach dem hinzufügen des secrets via kubectl können wir die Middleware definieren und über kubectl dem Cluster hinzufügen:
apiVersion: traefik.containo.us/v1alpha1kind: Middlewaremetadata: name: basic-auth namespace: kube-systemspec: basicAuth: secret: traefik-basic-authAls letzten Schritt müssen wir in der zuvor erstellen IngressRoute die Middleware mit aufnehmen:
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: traefik-dashboard namespace: kube-systemspec: entryPoints: - web routes: - match: Host(`traefik`) kind: Rule services: - name: api@internal kind: TraefikService middlewares: - name: traefik-basic-authSind die Änderungen übernommen, sollte eine Benutzernamen + Passwort Abfrage beim öffnen des Dashboards erscheinen.
IPWhiteList Middleware
Im nächsten Schritt werden wir unser Cluster für das Internet freigeben, wodurch auch Dritte das Cluster erreichen. Da ich im Cluster auch Anwendungen betreibe, die nicht über das Internet aufgerufen werden sollen, nutze ich die IPWhiteList Middleware um den Zugriff auf bestimmte IPs einzugrenzen:
apiVersion: traefik.containo.us/v1alpha1kind: Middlewaremetadata: namespace: kube-system name: private-ipsspec: ipWhiteList: sourceRange: - 127.0.0.1/32 - 192.168.178.0/24 - 10.42.0.0/16Diese Middleware blockiert alle Netzwerk-Anfragen von IP-Adressen, die nicht in der Liste definiert sind. Der dritte IP-Bereich (10.42.0.0/16) in der Liste, ist der von Kubernetes selbst und ich habe diesen hinzugefügt, falls andere Anwendungen im Cluster (z.B. Heimdall) das Dashboard aufrufen wollen.
Nach dem Anlegen der Middleware kann diese wie die Basic-Auth Middleware der IngressRoute hinzugefügt werden:
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: traefik-dashboard namespace: kube-systemspec: entryPoints: - web routes: - match: Host(`traefik`) kind: Rule services: - name: api@internal kind: TraefikService middlewares: - name: private-ips - name: traefik-basic-authCert-Manager
Für öffentliche Anwendungen empfiehlt es sich eine HTTPS-Verbindung zu nutzen, was in Zeiten von Let's Encrypt ohne großen Aufwand oder hohen Kosten funktioniert.
Bisher habe ich Traefik genutzt, um die Let's Encrypt TLS-Zertifikate zu generieren und zu verwalten. Dies funktionierte in meinem alten Docker-Compose Setup ohne Probleme. In einem Cluster Setup steht man aber vor der Herausforderung die generierten Zertifikate so zu speichern, dass sie für alle Nodes verfügbar sind. Anfänglich wollte ich einen verteilten Block-Storage nutzen, um die Zertifikate zu speichern. Der Block-Storage läuft aber im Read-Write-Once Modus, wodurch nur ein Pod Lesen und Schreiben Zugriff erhalten kann. Traefik läuft bei mir aber im DaemonSet Modus, wodurch ich mehr als einen Pod habe. Nach einer kurzen Recherche bin ich auf den Cert-Manager gestoßen, welcher ebenfalls Zertifikate über Let's Encrypt generiert und verwaltet. Anders als Traefik legt der Cert-Manager die Zertifikate als Secret ab, wodurch sie von allen Pods gelesen werden können.
Die Installation vom Cert-Manager findet über das offizielle Helm Chart statt:
kubectl create namespace cert-managerhelm repo add jetstack https://charts.jetstack.iohelm repo updatehelm install cert-manager jetstack/cert-manager --namespace cert-manager --version v1.2.0 --create-namespace --set installCRDs=trueNach der Installation muss ein ClusterIssuer erstellt werden, in welchem man eine E-Mail-Adresse für Let's Encrypt und eine Ingress-Class definiert. Den Namen der Ingress-Class wurde bereits bei der Installation von Traefik festgelegt (additionalArguments Option).
apiVersion: cert-manager.io/v1alpha2kind: ClusterIssuermetadata: name: letsencrypt-prodspec: acme: # You must replace this email address with your own. # Let's Encrypt will use this to contact you about expiring # certificates, and issues related to your account. email: <email-address> server: https://acme-v02.api.letsencrypt.org/directory privateKeySecretRef: # Secret resource used to store the account's private key. name: letsencrypt-prod solvers: - http01: ingress: class: traefik-cert-managerAufgrund des Rate-Limitings von Let's Encrypt empfiehlt es sich, einen zusätzlichen ClusterIssuer zu definieren welcher genutzt wird bis das Setup erfolgreich funktioniert. Dieser ClusterIssue nutzt die Stagging-Umgebung von Let's Encrypt, welche nicht in der Anzahl an Anfragen limitiert ist.
apiVersion: cert-manager.io/v1alpha2kind: ClusterIssuermetadata: name: letsencrypt-stagingspec: acme: # You must replace this email address with your own. # Let's Encrypt will use this to contact you about expiring # certificates, and issues related to your account. email: <email-address> server: https://acme-staging-v02.api.letsencrypt.org/directory privateKeySecretRef: # Secret resource used to store the account's private key. name: letsencrypt-staging solvers: - http01: ingress: class: traefik-cert-managerErste öffentliche Anwendung via HTTPS
Das Cluster ist soweit vorbereitet, um öffentliche Anwendungen per HTTPS zu betreiben, was jedoch noch fehlt ist das Einrichten von Port-Forwarding am Router und eine (Dyn)DNS-Adresse. Auf beides werde ich nicht im Detail eingehen, da das Setup sich je nach Router bzw. DNS-Anbieter unterscheidet. Wichtig ist, dass am Ende eingehender Datenverkehr über Port 80 und 443 an das Cluster weitergeleitet werden. Als Ziel-IP nutzt man die virtuelle Loadbalancer IP von Traefik. Auch wenn man nicht vorhat Anwendungen über HTTP zu betreiben, muss man dennoch den Port 80 für das Generieren von TLS Zertifikaten freigegeben. Anders als Traefik bietet der Cert Manager nämlich nur die Möglichkeit das Zertifikat über eine HTTP-Challenge zu generieren anstatt über eine TLS-Challenge.
Ist das Cluster öffentlich über Port 80 und 443 erreichbar, kann die erste öffentliche Anwendung installiert werden. Wir nutzen als Anwendung whoami von Traefik. Bei Whoami handelt es sich um einen kleinen Webserver, welcher HTTP Informationen zurückgibt.
Als erstes definieren wir ein Certificate-Objekt, welches die Generierung eines TLS-Zertifikats per Cert-Manager anstößt. Wurde das Zertifikat generiert, wird es als Secret mit dem Namen secure-whoami-cert gespeichert. Nutzt man den Cert-Manager das erste Mal, um ein Zertifikat zu generieren, sollte man erstmal den ClusterIssuer für die Staging Umgebung (letsencrypt-staging) nutzen anstatt direkt die Prod Umgebung (letsencrypt-prod) von Let's Encrypt zu nutzen.
Certificate
apiVersion: cert-manager.io/v1alpha2kind: Certificatemetadata: name: secure-whoami-certspec: commonName: demo.hierl.dev secretName: secure-whoami-cert dnsNames: - demo.hierl.dev issuerRef: name: letsencrypt-prod kind: ClusterIssuerAls nächstes wird das Deployment und der dazugehörige Service generiert
Deployment
apiVersion: apps/v1kind: Deploymentmetadata: name: whoamispec: replicas: 1 selector: matchLabels: app: whoami template: metadata: labels: app: whoami spec: containers: - image: containous/whoami name: whoami-container ports: - containerPort: 80 name: webService
apiVersion: v1kind: Servicemetadata: name: whoami labels: app: whoamispec: ports: - protocol: TCP name: web port: 8080 targetPort: web selector: app: whoamiAls letztes definieren wir eine IngressRoute um Whoami über Traefik nach außen verfügbar zu machen. Wichtig ist, dass die Domain in der Routing-Regel dieselbe ist wie im Certificate-Objekt und das beim Secret-Namen für TLS der definierte Secret-Name vom Certificate-Objekt eingetragen ist, da unter diesem Namen das TLS Zertifikat abgelegt wird.
IngressRoute
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: whoami-https labels: app: whoamispec: entryPoints: - websecure routes: - match: Host(`demo.hierl.dev`) kind: Rule services: - name: whoami port: 8080 tls: secretName: secure-whoami-certHat man alle YAML Dateien über kubectl übernommen, kann Whoami über eine HTTPS-Verbindung aufgerufen werden
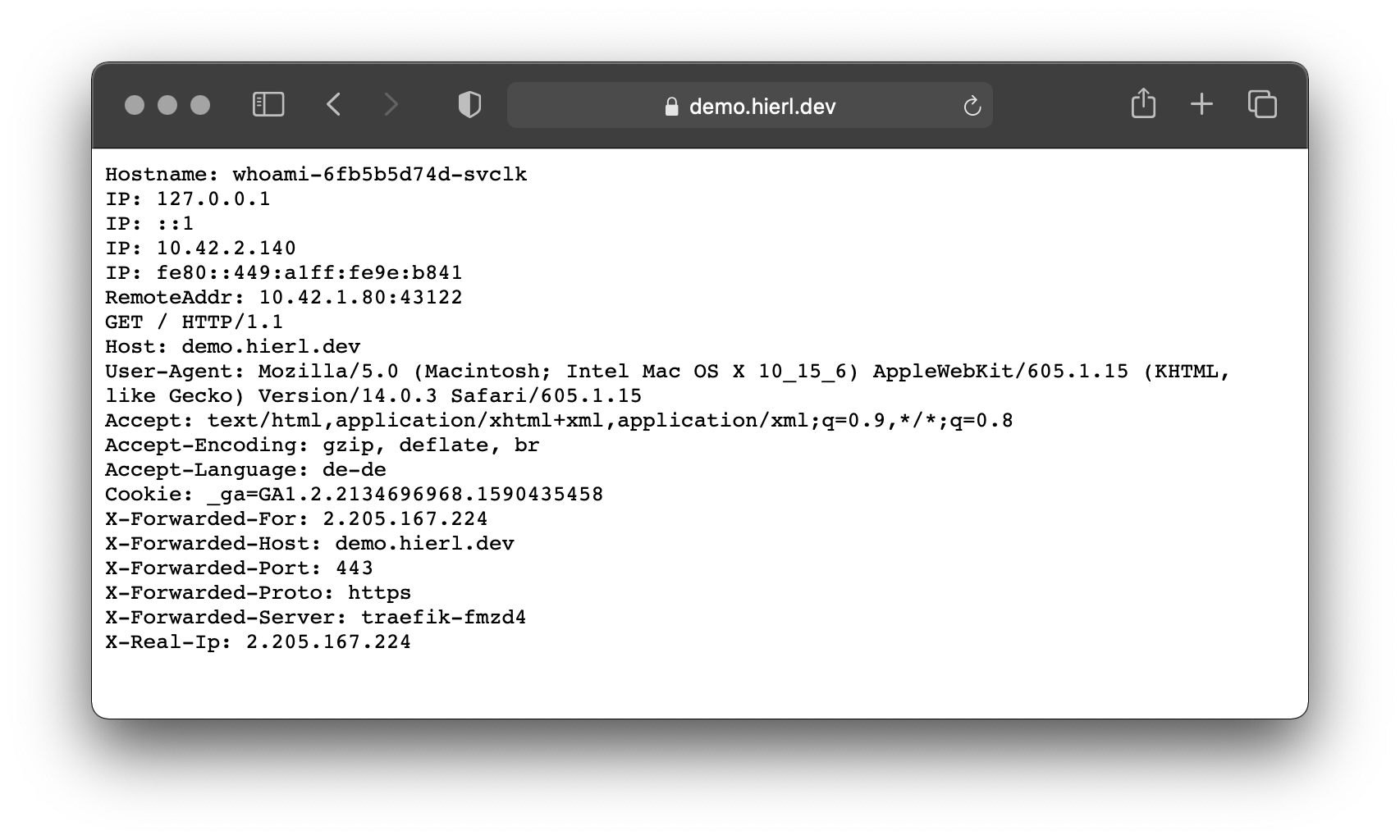
http to https redirect
Ruft man die Domain über HTTP anstatt HTTPS auf, erhält man einen 404 Fehler. Grund hierfür ist, dass die definierte IngressRoute nur für den Web Secure Endpoint (Port 443) gilt. Traefik bietet die Option an, alle Anfrage auf dem Web Endpoint (Port 80) auf den Web Secure Endpoint umzuleiten. Da ich aber interne Anwendungen nicht ohne größeren Aufwand über HTTPS betreiben kann und hier HTTP nutzen muss, kann ich diese Option nicht nutzen. Statt diese Umleitung zentral festzulegen, kann man mit einer Middleware pro IngressRoute festlegen ob auf HTTPS umgeleitet werden soll. Diese Middleware wendet man auf einer IngressRoute für den Web Endpoint an:
Middleware
apiVersion: traefik.containo.us/v1alpha1kind: Middlewaremetadata: name: https-only namespace: kube-systemspec: redirectScheme: scheme: httpsWeb Endpoint IngressRoute
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: whoami-http labels: app: whoamispec: entryPoints: - web routes: - match: Host(`demo.hierl.dev`) kind: Rule services: - name: whoami port: 8080 middlewares: - name: https-only namespace: kube-systemSecurity-Headers
Eine weitere interessante Middleware ist die Header Middleware, welche es erlaubt Security Response-Header zu setzen:
Middleware
apiVersion: traefik.containo.us/v1alpha1kind: Middlewaremetadata: namespace: kube-system name: security-headerspec: headers: frameDeny: true sslRedirect: true browserXssFilter: true contentTypeNosniff: true stsIncludeSubdomains: true stsPreload: true stsSeconds: 31536000IngressRoute
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: whoami-https labels: app: whoamispec: entryPoints: - websecure routes: - match: Host(`demo.hierl.dev`) kind: Rule services: - name: whoami port: 8080 middlewares: - name: security-header namespace: kube-system tls: secretName: secure-whoami-certLonghorn als verteilter Block-Storage
In einem Cluster-Setup steht man vor der Herausforderung Daten persistent zu speichern, den anders als bei einem Single-Node-Setup kann man nicht einfach einen lokalen Pfad auf dem Node definieren, unter welchem die Daten gespeichert werden soll. Denn Kubernetes kontrolliert welcher Pod auf welchem Node läuft und wenn Kubernetes einen Pod auf einen anderen Node verschiebt, weil der ursprüngliche Node nicht mehr verfügbar ist oder um eine bessere Lastverteilung zu haben, wandern die Daten nicht mit auf den neuen Node und der Pod kann nicht mehr auf die Daten zugreifen.
Abhilfe schafft an dieser Stelle Longhorn. Longhorn ist ein verteilter Block-Storage, welcher das Speicher-Management im Cluster übernimmt. Die Daten werden dabei auf mehreren Nodes repliziert und die Pods greifen indirekt über Longhorn auf die Daten zu. Für den Pod spielt es keine Rolle auf welchen Nodes die physischen Daten. Fällt ein Node aus, stehen die Daten durch die Replizierung weiterhin zur Verfügung und Pods die auf den noch verfügbaren Nodes hochgefahren werden, können weiterhin auf die Daten zugreifen. Steht der ausgefallene Node wieder zur Verfügung, kümmert sich Longhorn darum, dass die Daten zwischen allen Replicas syncronisiert werden, um wieder einen synchronen Zustand zu erreichen. Bis zu Version 1.1 unterstützte Longhorn nur den Modus Read-Write-Once, bei welchem nur ein Pod auf die Daten zugreifen darf. Wollen mehrere Pods auf denselben definierten Speicher-Volume zugreifen, kommt es zu einem Fehler. Seit Version 1.1 bietet Longhorn einen Read-Write-Many Modus an. Dieser Modus ist jedoch etwas komplizierter, weshalb wir erstmal beim Read-Write-Once Modus bleiben.
Longhorn lässt sich einfach über die offizielle YAML-Konfiguration installieren:
kubectl create namespace longhorn-systemkubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/master/deploy/longhorn.yamlIst Longhorn installiert, kann man ein Persistent-Volume-Claim (PVC) Objekt nutzen, um ein Volume für einen Pod zu definieren. In diesem Beispiel legen wir einen PVC mit dem Namen data-pvc an, welchem wir die Storage-Class "Longhorn" und 20 GB Speicher zuweisen:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: data-pvcspec: accessModes: - ReadWriteOnce storageClassName: longhorn resources: requests: storage: 20GiLonghorn legt daraufhin ein Replica an, welcher auf drei Nodes ein Volume anlegt. In einem Deployment können wir nun auf diesen PVC verweisen und Longhorn übernimmt das Speichern und Replizieren der Daten.
Longhorn bringt ein Web-Frontend mit, über welchen man Longhorn verwalten kann. Neben dem Anpassen von Einstellung, dem Verwalten von Volumes, hat man auch die Möglichkeit Snapshots oder Backups anzulegen bzw. kann für die automatische Erstellung von Snapshots und/oder Backups einen Job einrichten.
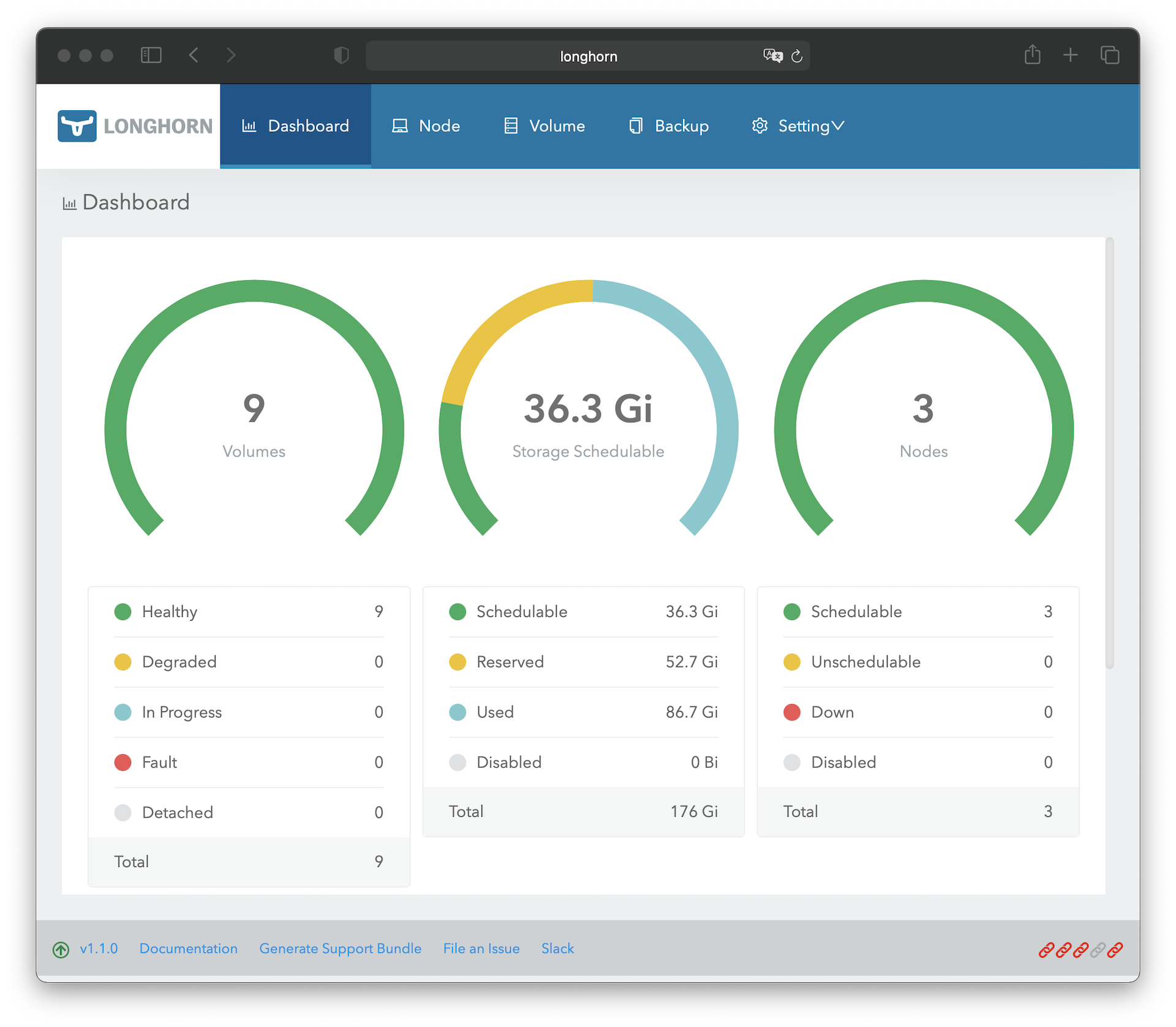
Um auf das Web-Frontend zugreifen zu können, muss noch eine IngressRoute angelegt werden. Da das Web-Frontend von Longhorn keinerlei Schutz mit sich, müssen wir in der IngressRoute wieder die Basic-Auth-Middleware nutzen und zusätzlich den Zugriff auf interne IP-Adressen begrenzen:
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: longhorn-frontend namespace: longhorn-systemspec: entryPoints: - web routes: - match: Host(`longhorn`) kind: Rule services: - name: longhorn-frontend port: 80 middlewares: - name: private-ips namespace: kube-system - name: traefik-basic-auth namespace: kube-systemDamit man das Web-Frontend von Longhorn vom eigenen Computer aufrufen kann, muss man den Hostname und IP-Adresse wie bereits bei Traefik zur lokalen Host-Datei hinzufügen. Da wir im nächsten Schritt aber auch einen DNS-Server installieren, kann man diesen Schritt erstmal überspringen.
Pi.Hole
Pi-hole ist ein Werbeblocker, welcher auf Netzwerk-Ebene operiert und DNS-Anfragen für Werbenetzwerke etc. blockiert. Dies hat den Vorteil, dass Werbung für alle Geräte im Netzwerk blockiert wird und auf den Geräten keine Software installiert werden muss. Neben Werbung lassen sich auch Tracking, Phishing, SPAM oder Malware Seiten blockieren. Pi-hole nimmt hierfür die Rolle eines DNS-Servers im Netzwerk ein und verarbeitet alle DNS-Anfragen aus dem Netzwerk. Fragt ein Gerät eine Domain, ab die auf einer Blockliste steht, wird die Anfrage mit einer ungültigen IP beantwortet, wodurch verhindert wird, dass mit dieser Domain kommuniziert werden kann. Alle erlaubten DNS-Abfragen werden an einen öffentlichen DNS-Server weitergeleitet, welcher dann die IP zur Domain zurückgibt. Neben dem Blocken von Werbung, Tracking etc. kann man Pi-hole aber auch nutzen, um eigene DNS-Einträge festzulegen, um so die Anwendungen im Cluster für das ganze Netzwerk erreichbar zu machen. Es ist dann nicht mehr notwendig auf dem eigenen Gerät die lokale Host-Datei anzupassen.
Das Setup von Pi-hole ist etwas umfangreicher als die vorherigen Setups, es werden aber nur bekannte Komponenten verwendet.
Persistent-Volume-Claim
Pi-Hole benötigt für den DNS-Cache und das Speichern der Einstellung zwei persistente Speicher:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: pihole-pvc-dataspec: accessModes: - ReadWriteOnce storageClassName: longhorn resources: requests: storage: 1Gi---apiVersion: v1kind: PersistentVolumeClaimmetadata: name: pihole-pvc-dnsmasqspec: accessModes: - ReadWriteOnce storageClassName: longhorn resources: requests: storage: 1GiSecret
Das Web-Interface von Pi-Hole wird durch ein Passwort geschützt, welches in einem Secret definiert wird:
apiVersion: v1kind: Secretmetadata: name: pihole-secrettype: OpaquestringData: password: <TBD>Deployment
In der Deployment-Definition legen wir fest, dass nur 1 Pod von Pi-Hole existieren darf (replicas = 1 und strategy = Recreate), da unser Speicher im ReadWriteOnce Modus läuft und mehrere Instanzen von PiHole zu einem Konflikt führen würden. Für das Web-Interface muss der Port 80 freigeben werden und für die DNS-Anfragen wird Port 53 benötigt. Da das DNS-Protokoll TCP und UDP verwendet, müssen wir für beide Protokolle ein Port-Mapping definieren. Über die Umgebungsvariablen teilen wir Pi-hole mit über welche IP der Dienst erreichbar ist, über welchen DNS-Namen wir das Web-Interface aufrufen wollen, welche Timezone verwendet werden soll und wie der Secret-Name für das Web-Interface-Passwort ist. Als letztes müssten noch die Mount Punkte definiert werden und mit den Persistent-Volume-Claims verknüpft werden und die Berechtigungen um die Rolle "NET_ADMIN" erweitert werden:
apiVersion: apps/v1kind: Deploymentmetadata: name: pihole-deployment labels: app: piholespec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: pihole template: metadata: labels: app: pihole spec: containers: - name: pihole image: pihole/pihole:latest imagePullPolicy: Always ports: - name: pi-admin containerPort: 80 protocol: TCP - containerPort: 53 name: dns-tcp protocol: TCP - containerPort: 53 name: dns-udp protocol: UDP env: - name: ServerIP value: "192.168.178.20" - name: VIRTUAL_HOST value: pi.hole - name: TZ value: 'Europe/Berlin' - name: WEBPASSWORD valueFrom: secretKeyRef: name: pihole-secret key: password volumeMounts: - name: pihole-data mountPath: /etc/pihole - name: pihole-dnsmasq mountPath: /etc/dnsmasq.d securityContext: capabilities: add: - NET_ADMIN volumes: - name: pihole-data persistentVolumeClaim: claimName: pihole-pvc-data - name: pihole-dnsmasq persistentVolumeClaim: claimName: pihole-pvc-dnsmasqServices
Für das Setup benötigen wir drei Services. Der erste Service ist für das Web-Interface, welches wir im Anschluss über eine IngressRoute erreichbar machen. Für den DNS-Service erstellen wir einen Service vom Typ "LoadBalancer" um wie bei Traefik eine virtuelle IP zu erhalten. Leider erlaubt es Kubernetes nicht in einem Service das TCP und UDP Protokoll zu nutzen, weshalb wir für beide einen eigenen Service definieren müssen. Damit beide Services dieselbe IP nutzen können, müssen wir MetalLB über eine Annotation mitteilen, dass definierte IP geteilt werden darf.
apiVersion: v1kind: Servicemetadata: name: pihole-admin-servicespec: type: ClusterIP selector: app: pihole ports: - protocol: TCP name: pihole-admin port: 80 targetPort: pi-admin---apiVersion: v1kind: Servicemetadata: name: pihole-service-udp annotations: metallb.universe.tf/allow-shared-ip: pihole-svcspec: type: LoadBalancer selector: app: pihole ports: - protocol: UDP name: dns-udp port: 53 targetPort: dns-udp loadBalancerIP: 192.168.178.21 externalTrafficPolicy: Local---apiVersion: v1kind: Servicemetadata: name: pihole-service-tcp annotations: metallb.universe.tf/allow-shared-ip: pihole-svcspec: type: LoadBalancer selector: app: pihole ports: - protocol: TCP name: dns-tcp port: 53 targetPort: dns-tcp loadBalancerIP: 192.168.178.21 externalTrafficPolicy: LocalIngressRoute
Die IngressRoute für das Web-Interface nutzt den Web Endpoint (HTTP / Port 80) und verwendet die private-ips Middleware, damit es nur aus dem internen Netzwerk aufgerufen werden kann.
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: pihole-ingress-routespec: entryPoints: - web routes: - match: Host(`pi.hole`) kind: Rule services: - name: pihole-admin-service port: 80 middlewares: - name: private-ips namespace: kube-systemSind alle Konfigurationen per kubectl übernommen worden, kann man die definierte IP-Adresse auf dem lokalen Computer als DNS-Server hinzufügen. Anschließend kann man das Web-Interface über http://pi.hole aufrufen. Hat man sich im Web-Interface angemeldet, stellt man im Bereich "Settings > DNS" den Upstream DNS-Server sein Wahl und die 'Conditional forwarding' Einstellungen ein. Anschließend kann man im Bereich "Local DNS > DNS Records" eigene DNS-Einträge definieren:
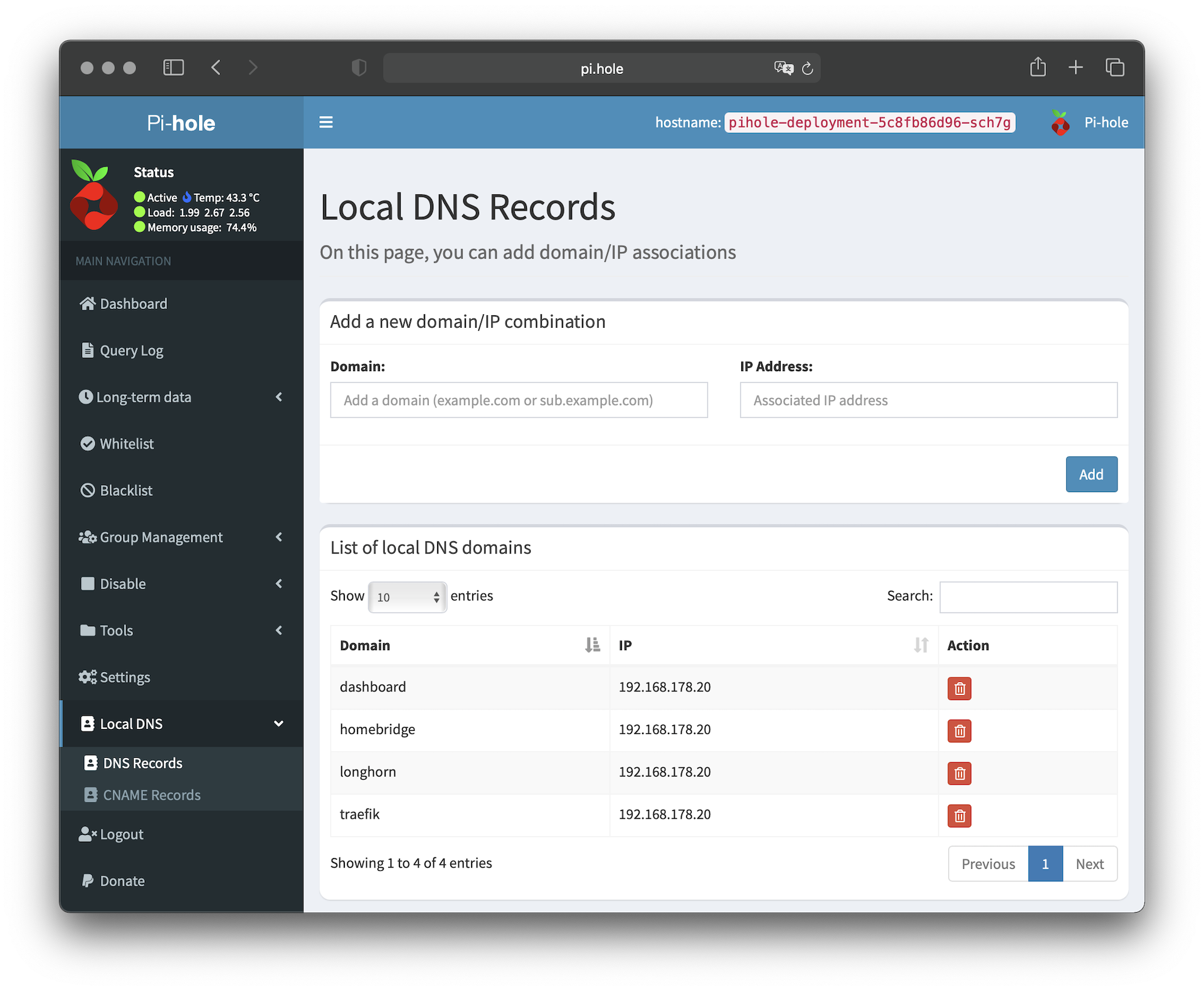
Sind die lokalen DNS-Einträge definiert, kann man die Einträge aus der lokalen Host-Datei wieder löschen. Im Bereich "Group Management > Adlists" kann man öffentliche Filter-Listen, die zum Blocken von Werbung, Tracking etc. genutzt werden, hinzufügen. Eine Sammlung von Filter-Listen findet man auf firebog.net.
Hat man Pi-hole nach den eigenen Wünschen eingerichtet und das Setup funktioniert auf dem lokalen Computer ohne Probleme, kann man im Router einstellen, dass alle Geräte im Netzwerk die IP Adresse von Pi-hole als DNS-Server nutzen sollen. Hierbei empfiehlt es sich, dass man nicht den Upstream DNS es Routers auf die IP von Pi-hole stellt, sondern in den DHCP Einstellungen den DNS-Server einträgt. So kommunizieren alle Geräte direkt mit Pi-hole und nicht erst mit dem Router, welcher dann mit Pi-hole kommuniziert.
Home Assistant
Home Assistant ist eine quelloffene Home-Automation Lösung, welche man selbst hosten kann und viele Automatisierungsmöglichkeiten bietet. Die Installation findet über einen Helm Chart statt.
Persistent-Volume-Claim
Vor der Installation von Helm-Chart lege ich einen Persistent-Volume-Claim an, in welchem die Daten und die SQLite Datenbank gespeichert werden. Zwar lässt sich der Persistent-Volume-Claim auch mittels Helm Chart direkt mit anlegen, aber falls ich Home-Assistant mal löschen müsste, würde der Persistent-Volume-Claim mit gelöscht werden. Um dies zu verhindern, lege ich den Persistent-Volume-Claim selbst an und verweise im Helm-Chart auf den existierenden Persistent-Volume-Claim.
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: homeassistant-pvc-dataspec: accessModes: - ReadWriteOnce storageClassName: longhorn resources: requests: storage: 1GiHelm Chart
Um die Installation anzupassen, wird wieder eine YAML-Datei benötigt. In dieser definieren wir die Timezone, deaktivieren das Anlegen einer IngressRoute, verweisen auf unseren Persistent-Volume-Claim und definieren unsere DNS-Server:
image: repository: homeassistant/home-assistant pullPolicy: IfNotPresent tag: latestenv: TZ: Europe/BerlincontrollerType: statefulsetstrategy: type: RollingUpdateresources: limits: cpu: 500m memory: 512Mi requests: cpu: 250m memory: 256Miingress: enabled: falsehostNetwork: trueservice: port: port: 8123dnsPolicy: ClusterFirstWithHostNetpersistence: config: enabled: true emptyDir: false existingClaim: "homeassistant-pvc-data"dnsConfig: nameservers: - 192.168.178.21 - 192.168.178.1Ist die YAML-Datei erstellt, können wir das Repo für den Helm-Chart hinzufügen und das Helm-Chart installieren:
helm repo add k8s-at-home https://k8s-at-home.com/charts/helm repo updatehelm upgrade --install home-assistant k8s-at-home/home-assistant -f values.yamlIngressRoute
In der IngressRoute für Home-Assistant legen wir wieder fest, dass nur interne IP-Adressen auf den Service hinzugreifen dürfen.
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: home-assistant-ingressspec: entryPoints: - web routes: - kind: Rule match: Host(`home-assistant`) middlewares: - name: private-ips namespace: kube-system services: - name: home-assistant port: 8123Ist die IngressRoute angelegt, muss in Pi-hole noch ein lokaler DNS-Eintrag für Home-assistant angelegt werden, um anschließend den Service über den festgelegten Hostname aufzurufen.
Wordpress Blog
Die nächste Anwendung, die wir im Cluster installieren ist ein öffentlicher WordPress-Blog. Das Setup für den Blog teilen wir in zwei Teile auf: Erst installieren wir die Datenbank Maria-DB und anschließend die WordPress-Anwendung. Der Grund für die Aufteilung ist, dass wir die Datenbank auch für andere Anwendungen im Cluster mit verwenden wollen.
MariaDB
Für die Datenbank legen wir als Erstes einen Persistent-Volume-Claim an, in welchem später die Daten gespeichert werden:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: mariadb-pvcspec: accessModes: - ReadWriteOnce storageClassName: longhorn resources: requests: storage: 5GiDie Installation findet wieder per Helm Chart statt, weshalb wieder eine YAML-Datei mit den Einstellungen erstellt werden muss. In der YAML Datei legen wir das root-passwort und verweisen auf unseren Persistent-Volume-Claim. Das Helm-Chart bietet die Möglichkeit bei der Installation eine Datenbank inkl. dazugehörigen Benutzer anzulegen. Alternativ kann man die Datenbank und den Benutzer später selbst anlegen.
service: type: ClusterIP port: 3306# Resource limits and requestsresources: limits: cpu: 1000m memory: 1024Mi requests: cpu: 300m memory: 512Mi## Database configurationsettings: ## The root user password (default: a 10 char. alpahnumerical random password will be generated) rootPassword: rootPasswort## Optional user database which is created during first startup with user and passworduserDatabase: { name: wordpress, user: wordpress, password: <Change-me>}## Storage parametersstorage: ## Set persistentVolumenClaimName to reference an existing PVC persistentVolumeClaimName: mariadb-pvcIst die YAML-Datei erstellt, kann man die Datenbank mit Helm Chart installieren:
helm repo add groundhog2k https://groundhog2k.github.io/helm-charts/helm repo updatehelm upgrade --install mariadb --values=mariadb-values.yaml groundhog2k/mariadbAnwendung
Für die Wordpress-Anwendung selbst benötigen wir ebenfalls einen Persistent-Volume-Claim, in welchem später Plugins, Fotos etc. gespeichert werden:
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: wordpress-pvcspec: accessModes: - ReadWriteOnce storageClassName: longhorn resources: requests: storage: 20GiIst der Persistent-Volume-Claim angelegt, nutzen wir auch hier wieder einen Helm-Chart, um die Anwendung zu installieren. Und wie auch bei der Datenbank legen wir vorher eine YAML-Datei an. In dieser legen wir die Rollout-Strategie, einige WordPress-Einstellungen, den Persistent-Volume-Claim und die Zugangsdaten für die Datenbank fest. Benutzernamen und Passwort für die Datenbank müssen den vorher festgelegten Daten entsprechen:
## Default values for Wordpress deploymentstrategy: type: Recreateservice: type: ClusterIP port: 80## Wordpress specific settingssettings: ## Database table name prefix tablePrefix: ## Maximum file upload size (default: 64M) maxFileUploadSize: 200M ## PHP memory limit (default: 128M) memoryLimit: 512Mresources: limits: cpu: 500m memory: 512Mi requests: cpu: 250m memory: 256Mi## Storage parametersstorage: ## Set persistentVolumenClaimName to reference an existing PVC persistentVolumeClaimName: wordpress-pvcexternalDatabase: ## Name of the database (default: wordpress) name: wordpress ## Database user user: wordpress ## Database password password: <change-me> ## Database host host: mariadbIst die YAML-Datei erstellt, kann die Anwendung installiert werden:
helm upgrade --install blog --values=wordpress-values.yaml groundhog2k/wordpressUm den Blog per HTTPS zu betreiben muss noch ein Zertifikat über den Cert-Manager generiert werde, wofür wir ein Certificate-Objekt definieren:
apiVersion: cert-manager.io/v1alpha2kind: Certificatemetadata: name: secure-wordpress-certspec: commonName: example-blog.com secretName: secure-wordpress-cert dnsNames: - example-blog.com issuerRef: name: letsencrypt-prod kind: ClusterIssuerNun ist alles so weit vorbereitet, dass man für den WordPress-Blog die Ingress Routen (HTTP und HTTPS) anlegen kann, um den Blog von außen zu erreichen:
apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: wordpress-http labels: app: wordpressspec: entryPoints: - web routes: - match: Host(`example-blog.com`) kind: Rule services: - name: blog-wordpress port: 80 middlewares: - name: https-only namespace: kube-system---apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata: name: wordpress-https labels: app: wordpressspec: entryPoints: - websecure routes: - match: Host(`example-blog.com`) kind: Rule services: - name: blog-wordpress port: 80 middlewares: - name: security-header namespace: kube-system tls: secretName: secure-wordpress-certDer WordPress-Blog sollte sich jetzt über die definierte Domain aufrufen lassen.
Zusammenfassung
In diesem Beitrag haben wir die Grundlagen für eine Handvoll von Anwendungen geschaffen und auch ein paar Beispiel-Anwendungen installiert. Die meisten Anwendungen lassen sich nach demselben Schema installieren und die Installation mit einem Helm-Chart nimmt einem viel Arbeit ab. In weiteren Beiträgen zu meinem Raspberry Pi Kubernetes Cluster werde ich auf Themen wie Function-as-a-Service (FaaS), Monitoring und Security eingehen.